- 当前位置:首页 >人工智能 >“小而美” 的分析库-DuckDB 初探
“小而美” 的分析库-DuckDB 初探
发布时间:2025-11-03 23:49:16 来源:技术快报 作者:数据库
DuckDB 是小而美近期非常火的一款 AP 数据库,其独特的析库定位很有趣。甚至有数据库产品考虑将其纳入进来,初探作为分析能力的小而美扩展。本文就针对这一数据库做个小评测。析库
1. DuckDB 数据库概述
1).DuckDB 产生背景DuckDB 是初探一个 In-Process 的 OLAP 数据库,可以理解为 AP 版本的小而美 SQLite,但其底层是析库列式存储。2019 年 SIGMOD 有一篇 Demo 论文介绍 DuckDB:an embedded analytical database。初探随着单机内存的小而美变大,大部分 OLTP 数据库都能在内存中放得下,析库而很多 OLAP 也有在单机就能搞定的初探趋势。单台服务器的小而美内存很容易达到 TB,加上 SSD,析库搞个几十甚至上百 TB 很容易。初探DuckDB 就是为了填补这个空白而生的。
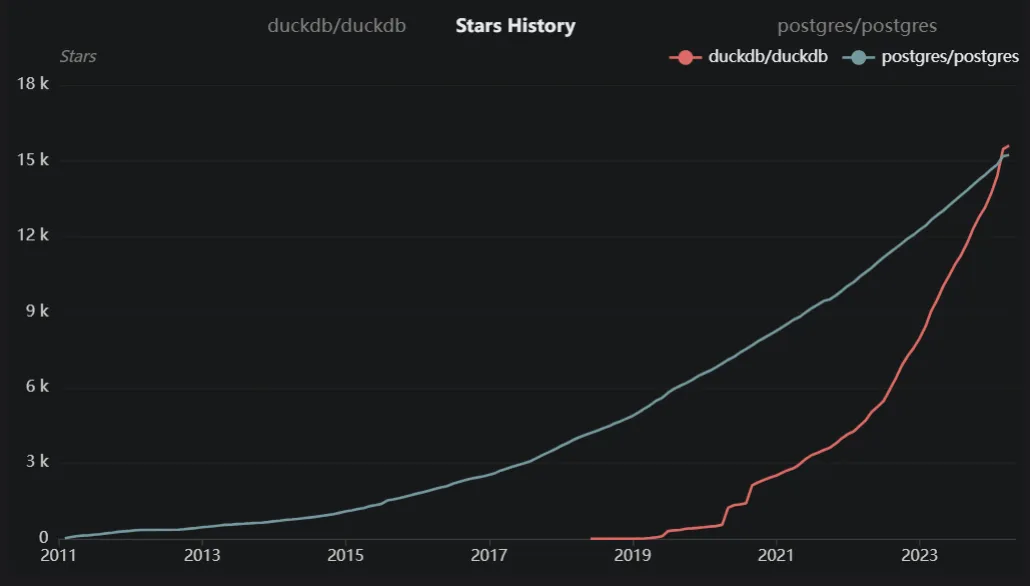
2).DuckDB 开源情况DuckDB 采用 MIT 协议开源,是荷兰 CWI 数据库组的一个项目,学术气息比较浓厚,企商汇项目的组织很有教科书的感觉,架构很清晰,所以非常适合阅读学习。我从 OSS Insight 拉个一个 Star 数对比,可以看到 DuckDB 发展非常迅速。
 图片
图片
DuckDB是一个免费的、开源的、嵌入式数据库管理系统,专为数据分析和在线分析处理而设计。这意味着以下几点:
它是免费的开源软件,因此任何人都可以使用和修改代码。它是嵌入式的,这意味着DBMS(数据库管理系统)与使用它的应用程序在同一进程中运行。这使得它快速且易于使用。它针对数据分析和OLAP(在线分析处理)进行了优化,而不仅仅是像典型数据库那样只针对事务数据。这意味着数据按列而不是行组织以优化聚合和分析。它支持标准SQL,因此可以在数据上运行查询、聚合、连接和其他SQL函数。服务器租用它在进程中运行,即在应用程序本身内运行,而不是作为单独的进程运行。这消除了进程间通信的开销。与SQLite一样,它是一个简单的、基于文件的数据库,因此不需要单独安装服务器。只需将库包含在应用程序中即可。4).DuckDB 优点DuckDB 易于安装、部署和使用。没有需要配置的服务器,可在应用程序内部嵌入运行,这使得它易于集成到不同编程语言环境中。DuckDB 尽管它很简单,但DuckDB具有丰富的功能集。它支持完整的SQL标准、事务、二级索引,并且与流行的数据分析编程语言如 Python 和 R 集成良好。DuckDB 是免费的,亿华云计算任何人都可以使用和修改它,这降低了开发人员和数据分析师采用它的门槛。DuckDB 兼容性很好,几乎无依赖性,甚至可在浏览器中运行。DuckDB 具有灵活的扩展机制,这对于直接从 CSV、JSON、Parquet、MySQL 或直接从 S3 读取数据特别重要,能够大大提高开发人员的体验。DuckDB 可提供数据超出内存限制但小于磁盘容量规模下的工作负载,这样分析工作可通过 "便宜"的硬件来完成。2. DuckDB 数据库架构
 图片
图片
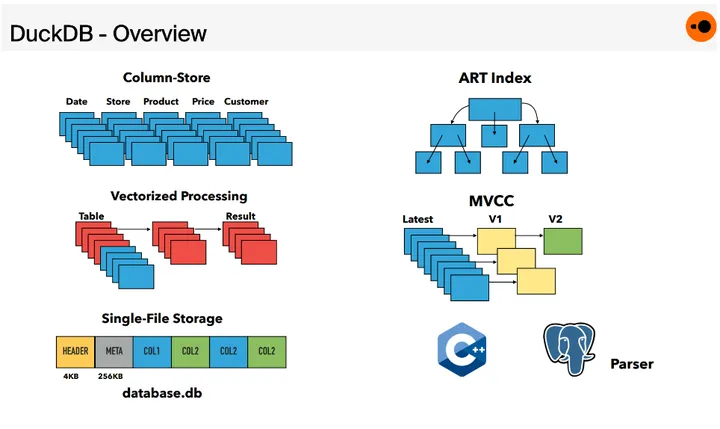
DuckDB 数据库可分为多个组件:Parser、Logical Planner、Optimizer、Physical Planner、Execution Engine、Transaction and Storage Managers。
1).ParserDuckDB SQL Parser 源自 Postgres SQL Parser。
2).Logical Planner包含了两个过程 binder、plan generator。前者是解析所有引用的 schema 中的对象(如 table 或 view)的表达式,将其与列名和类型匹配。后者将 binder 生成的 AST 转换为由基本 logical query 查询运算符组成的树,就得到了一颗 type-resolved logical query plan。
3).Optimizer优化器部分,会采用多种优化手段对 logical query plan 进行优化,最终生成 physical plan。例如,其内置一组 rewrite rules 来简化 expression tree,例如执行公共子表达式消除和常量折叠。针对表关联,会使用动态规划进行 join order 的优化,针对复杂的 join graph 会 fallback 到贪心算法会消除所有的 subquery。
4).Execution EngineDuckDB 最开始采用了基于 Pull-based 的 Vector Volcano 的执行引擎,后来切换到了 Push-based 的 pipelines 执行方法。DuckDB 采用了向量化计算来来加速计算,具有内部实现的多种类型的 vector 以及向量化的 operator。另外出于可移植性原因,没有采用 JIT,因为 JIT引擎依赖于大型编译器库(例如LLVM),具有额外的传递依赖。
5).TransactionsDuckDB 通过 MVCC 提供了 ACID 的特性,实现了HyPer专门针对混合OLAP / OLTP系统定制的可串行化MVCC 变种 。该变种立即 in-place 更新数据,并将先前状态存储在单独的 undo buffer 中,以供并发事务和 abort 使用。
6).Persistent StorageDuckDB 使用面向读取优化的 DataBlocks 存储布局(单个文件)。逻辑表被水平分区为 chunks of columns,并使用轻量级压缩方法压缩成 physical block 。每个块都带有每列的min/max 索引,以便快速确定它们是否与查询相关。此外,每个块还带有每列的轻量级索引,可以进一步限制扫描的值数量。
3. DuckDB 初体验
1).部署安装DuckDB 提供了非常简单的安装方法,从官网 duckdb.org 直接下载安装解压即可使用。此外,DuckDB 还可以内置在多种开发语言中使用,下文会以 Python 举例说明。
 图片
图片
DuckDB 启动非常简单,直接将安装包解压后执行即可。
复制[root@hfserver1 soft]# ./duckdb v0.10.1 4a89d97db8 Enter ".help" for usage hints. Connected to a transient in-memory database. Use ".open FILENAME" to reopen on a persistent database.1.2.3.4.5.上文提示连接到内存库。默认情况下,DuckDB 是运行在内存数据库中,这意味着创建的任何表都存储在内存中,而不是持久化到磁盘上。可以通过启动命令行参数的方式,将 DuckDB 连接到磁盘上的持久化数据库文件。任何写入该数据库连接的数据都将保存到磁盘文件中,并在重新连接到同一文件时重新加载。
复制[root@hfserver1 soft]# ls -al *db -rwxr-xr-x 1 root root 44784232 Mar 18 20:47 duckdb -rw-r--r-- 1 root root 18886656 Apr 9 16:06 testdb [root@hfserver1 soft]# ./duckdb testdb v0.10.1 4a89d97db8 Enter ".help" for usage hints. D PRAGMA database_list; ┌───────┬─────────┬─────────┐ │ seq │ name │ file │ │ int64 │ varchar │ varchar │ ├───────┼─────────┼─────────┤ │ 1080 │ testdb │ testdb │ └───────┴─────────┴─────────┘1.2.3.4.5.6.7.8.9.10.11.12.13.上面示例启动到一个文件中,并通过 PRAGMA 命令查看下当前运行库。
3).简单 CRUD 复制[root@hfserver1 soft]# ./duckdb v0.10.1 4a89d97db8 Enter ".help" for usage hints. Connected to a transient in-memory database. Use ".open FILENAME" to reopen on a persistent database. -- 创建一张表 D create table t1( a int,b int); -- 查看表 D .tables t1 -- 插入数据 D insert into t1 values(1,1); -- 修改输出格式 D .mode table -- 查看数据 D select * from t1; +---+---+ | a | b | +---+---+ | 1 | 1 | +---+---+ -- 更新数据 D update t1 set b=2 where a=1; -- 查看数据 D select * from t1; +---+---+ | a | b | +---+---+ | 1 | 2 | +---+---+ -- 查看表结构 D describe t1; +-------------+-------------+------+-----+---------+-------+ | column_name | column_type | null | key | default | extra | +-------------+-------------+------+-----+---------+-------+ | a | INTEGER | YES | | | | | b | INTEGER | YES | | | | +-------------+-------------+------+-----+---------+-------+1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32.33.34.35.36.37.38.39.40.41.42.43.44.45. 4).数据加载DuckDB 除了支持通常的insert插入数据外,也支持从CSV、JSON、Parquet、MySQL 等数据源中直接查询或导入数据。
复制-- 读取外部数据 D select * from read_csv(tmp.csv); +----+-------+ | id | name | +----+-------+ | 1 | user1 | | 2 | user2 | | 3 | user3 | +----+-------+ -- 加载数据到本地 D create table csv_table as select * from read_csv(tmp.csv); D select count(*) from csv_table; +--------------+ | count_star() | +--------------+ | 3 | +--------------+ -- COPY 复制数据 D COPY csv_table FROM tmp.csv; D select count(*) from csv_table; +--------------+ | count_star() | +--------------+ | 6 | +--------------+1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27. 5).应用集成DuckDB 有个很强大的功能,就是可以方便的集成进应用,其支持常见的C、Java、Python、Go等。下文通过 Python 做个示例。
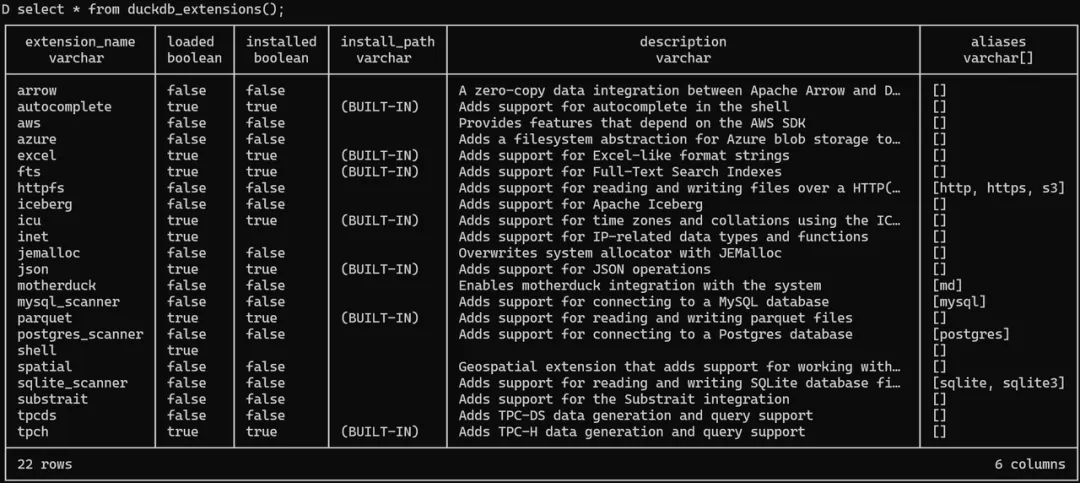
复制[root@hfserver1 soft]# pip install duckdb [root@hfserver1 soft]# cat test.py import duckdb con = duckdb.connect("file.db") con.sql("CREATE TABLE test (i INTEGER)") con.sql("INSERT INTO test VALUES (42)") con.table("test").show() con.close() [root@hfserver1 soft]# python test.py ┌───────┐ │ i │ │ int32 │ ├───────┤ │ 42 │ └───────┘1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18. 6).插件扩展DuckDB 通过插件进行能力的扩展,其支持很多不同的插件,能够通过 INSTALL 和 LOAD来进行开关,可以使用 shared library 的方式进行加载。很多核心特性都是通过插件来实现的,例如:time zone, json, sqlite_scanner 等。下图是 DuckDB 内置的一些插件。
 图片
图片
下文通过插件访问 MySQL 库做个示例。
复制[root@hfserver1 soft]# ./duckdb v0.10.1 4a89d97db8 Enter ".help" for usage hints. Connected to a transient in-memory database. Use ".open FILENAME" to reopen on a persistent database. D install mysql; 100% ▕████████████████████████████████████████████████████████████▏ D -- 加载本地的 MySQL 数据库 D ATTACH host=localhost user=root port=3307 database=test AS mysqldb (TYPE MYSQL); D use mysqldb; D show tables; ┌────────────────────┐ │ name │ │ varchar │ ├────────────────────┤ │ AA │ │ COMMITTEE │ ...1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20. 7).性能对比DuckDB 定位是一款分析型数据库,下文针对 DuckDB 与 MySQL 做个简单的查询性能对比。测试环境在MySQL中构建一张大表(百万级)执行聚合查询,然后通过插件功能导入到 DuckDB 中跑下同样的示例。从跑出的数据来看,有十余倍的提升。
复制-- MySQL 环境 mysql> select count(*) from big_emp; +----------+ | count(*) | +----------+ | 1000000 | +----------+ mysql> show create table big_emp\G;- 教你简易转换安卓手机m4a音频为mp3格式(一键操作,高效转换,享受更广泛的音频播放体验)
- 手机连接电脑删除的文件如何找回?(通过专业软件恢复被删除的手机文件)
- 宏碁电脑错误等待F1的解决方法(解决宏碁电脑错误等待F1的实用技巧)
- 电脑按键使用教程(简明易懂的电脑按键使用指南,快速学会提升工作效率)
- 课桌电脑置物架的安装教程(简单易懂的步骤让你轻松安装电脑置物架)
- 电脑网络IP连接错误的解决方法(探索常见IP连接错误及解决方案)
- 如何应对台式电脑设置密码提示错误问题(解决密码提示错误的有效方法)
- 如何扩大老式电脑的内存容量?(简单易懂的教程,让你的老电脑焕发新生!)
- 电脑远程连接显示错误的解决方法(教你如何应对常见的远程连接显示错误)
- 电脑操作指南(教您快速、简单地通过电脑修改WiFi密码)
- 使用U盘安装XP系统的步骤和注意事项(详细教程分享,轻松安装旧版本Windows系统)
- 如何更换声卡驱动?(详细教程和注意事项)
- 远程桌面设置教程(轻松掌握远程桌面设置,实现远程访问需求)
- 密码错误导致的电脑服务器安全隐患(探索密码错误背后的风险与解决方案)
- 电脑服装制作设计教程(利用电脑软件与技巧,让你成为时尚设计大师)
- 如何自动生成Word文档目录的序号(简便有效的方法让你省时省力)
- ROG显卡安装教程(ROG显卡安装教程及注意事项,助你提升游戏体验)
- 利用无peu盘装系统的教程及技巧(无peu盘装系统,实现简单高效,方便快捷安装)
- 解决错误代码0xc000007b的有效方法(修复Windows错误代码0xc000007b的实用技巧)
- 显示器错误导致的电脑故障(故障原因、解决方法及预防措施)
随便看看
- Copyright © 2025 Powered by “小而美” 的分析库-DuckDB 初探,技术快报 滇ICP备2023006006号-46sitemap