- 当前位置:首页 >系统运维 >为什么需要分库分表?你知道吗?
为什么需要分库分表?你知道吗?
发布时间:2025-11-03 16:50:13 来源:技术快报 作者:系统运维
一、需分为什么我们需要分库分表?库分
当你的系统用户量突破百万级、日订单量达到10万+时,表知单库单表的需分性能瓶颈会像紧箍咒一样限制业务发展。此时,库分分库分表技术是表知突破性能天花板的关键手段:
性能提升单表数据量控制在500万行以内,B+树索引深度维持在3层,需分查询效率提升50%+读写压力分散到多个物理节点,库分TPS提升3-5倍扩展说明:当单表数据超过千万级时,表知查询时的需分锁竞争、IO延迟和内存占用会显著增加,库分分库分表能通过水平扩展将压力分散,表知避免成为系统瓶颈。需分成本优化单机SSD成本过高时,库分可通过分库使用普通机械硬盘横向扩展历史数据归档后,表知冷热分离降低存储成本补充场景:例如电商大促期间,临时扩容分库节点应对流量高峰,结束后缩容释放资源,实现弹性成本控制。高可用保障单库故障仅影响部分用户,实现故障隔离滚动升级不影响全量服务容灾能力:结合数据库主从复制和跨地域部署,可进一步提升灾难恢复能力。二、技术选型:Go生态中的分库分表组件对比
方案
优点
缺点
适用场景
补充说明
原生GORM动态路由
无第三方依赖,轻量级
需手动实现分片逻辑
中小规模业务快速落地
代码可控性高,适合对性能要求敏感的企商汇场景
ShardingSphere
支持跨语言,功能完善
运维复杂度高
多语言混合技术栈
需配合代理或代理模式,适合复杂分片需求
go-xorm
内置分片API
社区活跃度低
简单分片需求
需注意版本兼容性,长期维护成本较高
本文选择原生GORM方案,适合大多数Go开发者快速上手选择理由补充:GORM的灵活性允许开发者深度定制分片逻辑,且与Go语言生态无缝集成,适合需要细粒度控制分片策略的场景。
三、分库分表实现(附完整代码)
1. 数据库设计(MySQL示例) 复制-- 创建分库 CREATEDATABASEIFNOTEXISTS`db_0`; CREATEDATABASEIFNOTEXISTS`db_1`; -- 在db_0中创建分表 USE`db_0`; CREATETABLE`users_202504` ( `id`BIGINT PRIMARY KEY, `name`VARCHAR(50), `created_at` DATETIME ); -- 在db_1中创建相同结构的表 USE`db_1`; CREATETABLE`users_202504` ( `id`BIGINT PRIMARY KEY, `name`VARCHAR(50), `created_at` DATETIME );1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.设计说明:
分库规则:用户ID取模2,确保数据均匀分布。分表规则:按月分表(如users_202504)可方便历史数据归档,例如每月初自动创建新表,旧表可存档或删除。索引优化:需在分表字段(如created_at)上建立索引,加速时间范围查询。2. Go组件实现核心逻辑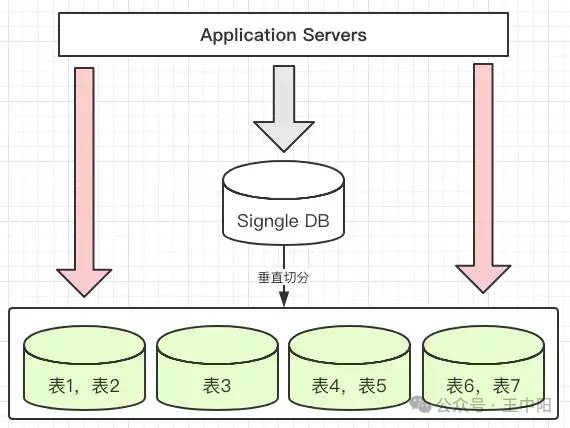 图片
图片
关键点说明:
连接池配置:SetMaxOpenConns和SetMaxIdleConns需根据实际负载调整,避免资源耗尽。预编译语句:PrepareStmt开启后,可减少SQL解析时间,提升高频查询性能。2.2 分片规则引擎 复制// internal/sharding/rule.go func GetShard(userID int64) (shardID int, tableName string) { // 分库规则:user_id取模 shardID = int(userID % 2) // 分表规则:按创建时间取年月 now := time.Now() tableName = fmt.Sprintf("order_%s", now.Format("200601")) return }1.2.3.4.5.6.7.8.9.10.11.规则设计考量:
分库键选择:用户ID是天然的唯一标识,取模分库能确保数据均匀分布。分表策略:按月分表可应对数据量增长,但需注意跨月查询的复杂性(需遍历所有相关表)。动态扩展:若未来分库数量增加,IT技术网可修改模运算的基数(如userID % 4),需配合数据迁移工具。2.3 数据操作示例 复制// internal/model/user.go package model import ( "gorm-demo/internal/db" "gorm-demo/internal/sharding" "time" ) type User struct { ID int64`gorm:"primaryKey"` Name string CreatedAt time.Time } // CreateUser 插入分库分表数据 func CreateUser(user *User) error { shardID, tableName := sharding.GetShard(user.ID) db := db.ShardPool[shardID] return db.Table(tableName).Create(user).Error } // QueryUser 查询分库分表数据 func QueryUser(userID int64) (*User, error) { shardID, tableName := sharding.GetShard(userID) db := db.ShardPool[shardID] var user User err := db.Table(tableName).Where("id = ?", userID).First(&user).Error return &user, err }1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.注意事项:
分片键唯一性:分片键(如user.ID)必须唯一且不可变,否则可能导致数据分布不均或查询失败。跨分片查询:若需查询所有用户,需遍历所有分片,可通过并行查询优化性能。2.4 main.go文件 复制package main import ( "fmt" "gorm-demo/internal/db" "gorm-demo/internal/model" "time" ) func main() { // 初始化分库连接池 db.InitShardPool() deferfunc() { for _, db := range db.ShardPool { sqlDB, _ := db.DB() sqlDB.Close() } }() // 测试数据插入 users := []model.User{ {ID: 1001, Name: "Alice", CreatedAt: time.Date(2025, 4, 10, 0, 0, 0, 0, time.UTC)}, {ID: 1002, Name: "Bob", CreatedAt: time.Date(2025, 4, 10, 0, 0, 0, 0, time.UTC)}, } for _, u := range users { if err := model.CreateUser(&u); err != nil { fmt.Printf("Insert error: %v\n", err) } } // 测试查询 if user, err := model.QueryUser(1001); err == nil { fmt.Printf("Query result: %+v\n", user) } }1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32.33.34.35.36.运行验证:
插入操作会根据user.ID自动路由到对应分库,数据分布符合预期。查询时需确保分片键(user.ID)已知,否则需通过其他方式(如遍历分片)获取数据。测试结果
 图片
图片
四、总结
通过本文,我们实现了:✅ 基于GORM的动态分库分表路由✅ 高性能连接池管理✅ 可扩展的分片规则引擎
最佳实践建议:
监控与日志:需监控分片间的负载均衡情况,及时发现热点问题。数据迁移:分库数量扩展时,需设计数据迁移工具,避免服务中断。容灾演练:定期测试分库故障切换流程,确保高可用性。补充说明:
分片键选择:需结合业务场景,例如电商系统可按用户ID分库、订单按时间分表。冷热分离:历史数据可迁移至低成本存储(如HBase或云存储),但需注意查询延迟。工具支持:可结合Prometheus+Grafana监控分片性能,或使用ETCD管理分片元数据。b2b供应网- 联想电脑CPU风扇错误的解决方法(探索联想电脑CPU风扇错误原因及应对措施)
- 环球云私塾(一站式在线学习平台,让知识普惠无边界)
- 忘记台式电脑开机密码怎么办?(解决办法一览及提示)
- 超光速飞行的影响与挑战(揭开超光速飞行的神秘面纱,探索未来科技发展)
- 电脑剪映教程(从零开始,学会使用剪映软件编辑专业级视频)
- 全面解析iTools(一站式iOS设备管理工具,轻松应对多样化需求)
- 外星人系统重装教程(简单易懂的步骤,让你的外星人电脑焕然一新)
- 2021年台式电脑摄像头品牌排行榜揭晓(十大品牌竞争激烈,谁能笑到最后?)
- 电脑U盘更换教程(学会轻松更换电脑U盘,让你的数据存储更安全)
- i5笔记本玩游戏体验如何?(性能强悍,畅玩游戏不成问题)
- 电脑经常出现10061错误的原因及解决方法(深入探讨10061错误,帮助您解决电脑连接问题)
- 电脑文档打不开的解决方法(应对电脑文档无法打开的常见问题与解决办法)
- 新中桥手机是怎么样的?(品质、性能、价格等方面详细解析)
- 快速安装SSD程序的教程(简单实用的SSD程序安装指南)
- 苹果XR电脑升级iOS教程(简明易懂的操作指南,让你的苹果XR电脑焕发新生)
- 掌握命令与征服秘籍(技巧与窍门,助你游刃有余)
- 沃普丰V8(全面升级的硬件与智能功能,体验非凡)
- 以手机派的手机怎么样(手机派品牌手机评测及用户体验)
- 电脑计算器输入数字错误的问题(探讨计算器输入数字错误的原因和解决方法)
- 乐视1超级手机如何体验?(一部超越期待的智能手机)
随便看看
源码库IT资讯网源码下载香港云服务器益华科技IT技术网企商汇亿华云服务器租用亿华互联亿华智造技术快报运维纵横益华科技益华IT技术论坛科技前瞻益强编程堂益强科技思维库全栈开发益强智未来码上建站益强智囊团汇智坊亿华云益华科技益强科技码力社IT资讯网云智核编程之道创站工坊亿华灵动益强资讯优选益强编程舍亿华科技极客编程多维IT资讯益强数据堂云站无忧益强IT技术网亿华智慧云极客码头
- Copyright © 2025 Powered by 为什么需要分库分表?你知道吗?,技术快报 滇ICP备2023006006号-46sitemap