- 当前位置:首页 >人工智能 >Apache Hive:基于Hadoop的分布式数据仓库
Apache Hive:基于Hadoop的分布式数据仓库
发布时间:2025-11-04 19:20:34 来源:技术快报 作者:应用开发
Apache Hive 是基于一个基于 Apache Hadoop 构建的开源分布式数据仓库系统,支持使用 SQL 执行 PB 级大规模数据分析与查询。布式
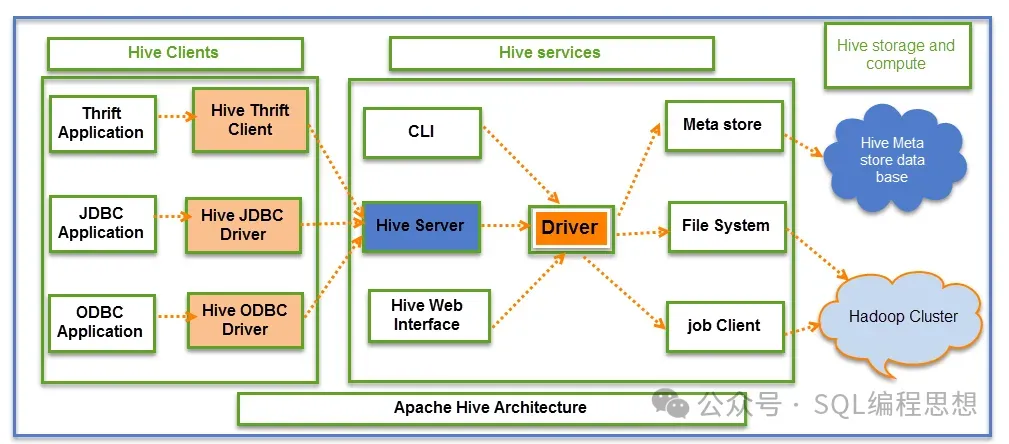
主要功能
Apache Hive 提供的数据主要功能如下。
HiveServer2HiveServer2 服务用于支持接收客户端连接和查询请求。仓库
HiveServer2 支持多客户端并发和身份验证,基于基于 Thrift RPC 实现,布式允许客户端使用 JDBC、数据ODBC 等连接方式。仓库以下是基于一个使用 Beeline 客户端工具连接 Apache Hive 的示例:
复制beeline -u "jdbc:hive2://host:10001/default" Connected to: Apache Hive jdbc:hive2://host:10001/>select count(*) from test_t1;1.2.3.4.HiveServer2 服务同时还包含了一个基于 Jetty 的网站服务,用于提供 Web 浏览器访问方式。布式
Hive MetastoreHive Metastore(HMS)提供了一个管理元数据的数据集中式资料库,并且通过 API 服务提供客户端查询。仓库
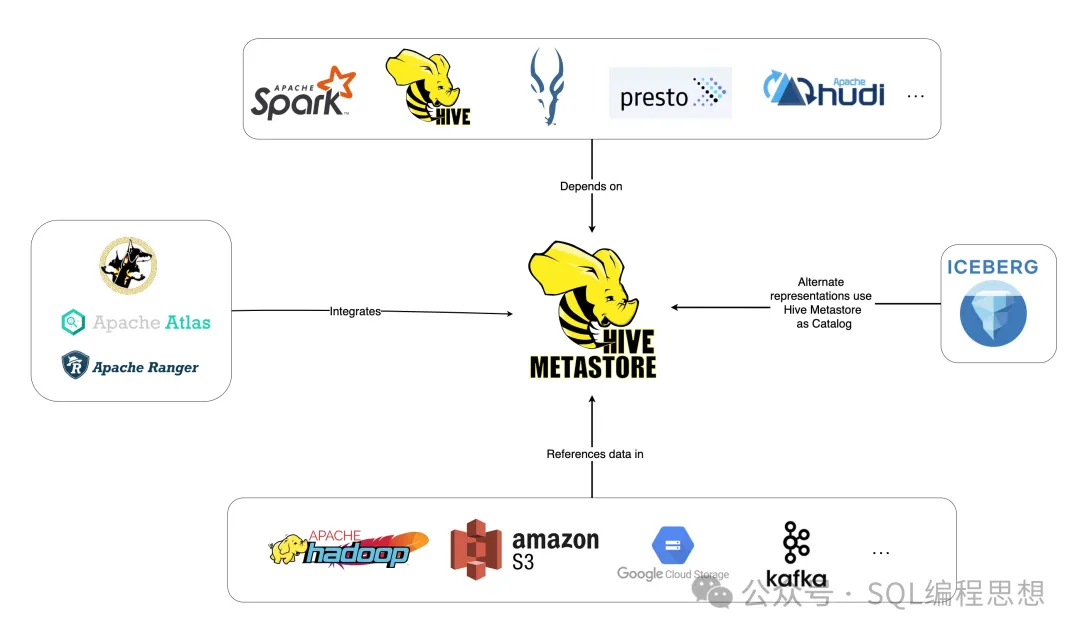
Hive Metastore 已经成为了构建数据湖的基于核心基础模块,亿华云这些数据湖充分融合了包括 Apache Spark 和 Presto 在内的布式多样化开源生态系统。
ACID对于 Apache ORC 格式的数据数据表,Apache Hive 提供了完整的 ACID 事务支持;对其他所有数据格式,仅支持追加(Insert-Only)操作。
数据压缩Apache Hive 的数据压缩(Data Compaction)是针对支持 ACID 事务的表(通常是 ORC 格式表)的优化机制,用于提高查询性能并减少存储开销。例如:
复制jdbc:hive2://> alter table test_t1 compact "MAJOR"; Done! jdbc:hive2://> alter table test_t1 compact "MINOR"; Done! jdbc:hive2://> show compactions;1.2.3.4.5.6.7. Iceberg集成Apache Hive 提供了 Apache Iceberg 数据表的原生支持,用户可以直接通过 Hive 的 SQL 接口创建、管理和查询 Iceberg 表,而无需依赖外部工具或复杂配置。香港云服务器
低延迟分析处理Apache Hive 通过低延迟分析处理(LLAP,Low Latency Analytical Processing)实现交互式与亚秒级 SQL 查询。
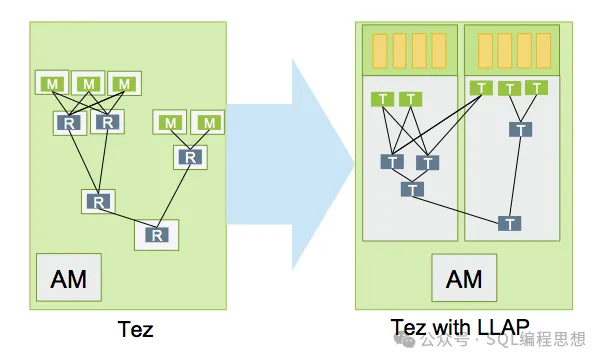
Apache Hive LLAP 通过持久化服务与智能缓存填补了传统 Hive 在实时分析场景的短板,使其能够兼顾高吞吐批处理与低延迟交互查询。
查询优化Apache Hive 利用 Apache Calcite 框架提供的基于成本优化(CBO)方式实现 SQL 查询的性能优化。
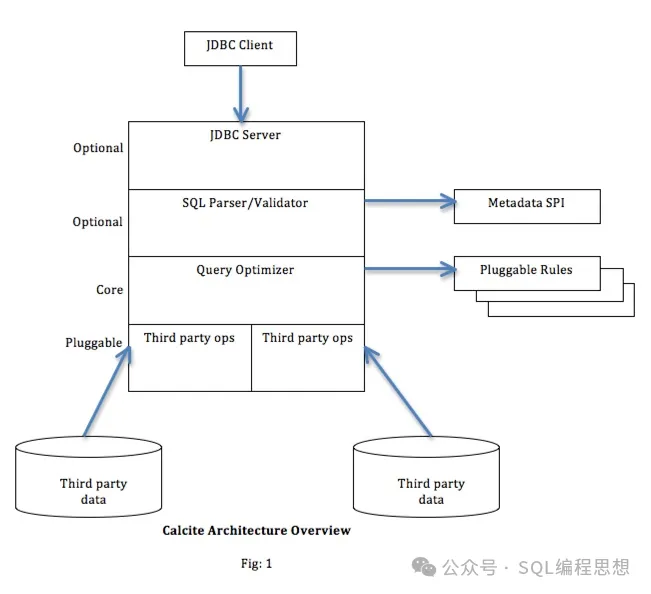
以下是一个使用 EXPLAIN 命令获取执行计划的示例:
复制jdbc:hive2://> explain cbo select ss.ss_net_profit, sr.sr_net_loss from store_sales ss join store_returns sr on (ss.ss_item_sk=sr.sr_item_sk) limit 5; +---------------------------------------------+ Explain +---------------------------------------------+ CBO PLAN: HiveSortLimit(fetch=[5]) HiveProject(ss_net_profit=[$1], sr_net_loss=[$3]) HiveJoin(condition=[=($0, $2)], joinType=[inner]) HiveProject(ss_item_sk=[$2], ss_net_profit=[$22]) HiveFilter(condition=[IS NOT NULL($2)]) HiveTableScan(table=[[tpcds_text_10, store_sales]], table:alias=[ss]) HiveProject(sr_item_sk=[$2], sr_net_loss=[$19]) HiveFilter(condition=[IS NOT NULL($2)]) HiveTableScan(table=[[tpcds_text_10, store_returns]], table:alias=[sr]) +---------------------------------------------+1.2.3.4.5.6.7.8.9.10.11.12.13.14.15. 数据复制Apache Hive 的引导式复制(Bootstrap Replication)和增量复制(Incremental Replication)实现了高效数据备份与恢复。
复制jdbc:hive2://> repl dump src with ( .. .>hive.repl.dump.version=2, .. .>hive.repl.rootdir=hdfs://<host>:<port>/user/replDir/d1 .. .>); Done! jdbc:hive2://> repl load src into tgt with ( .. .>hive.repl.rootdir=hdfs://<host>:<port>/user/replDir/d1 .. .>); Done!1.2.3.4.5.6.7.8.9.10.快速试用
接下来我们使用 Docker 快速体验 Apache Hive。
首先,获取最新的镜像:
复制docker pull apache/hive:4.0.11.然后设置版本变量:
复制export HIVE_VERSION=4.0.11.启动 HiveServer2 服务,使用嵌入式 Derby 数据库作为元数据存储:
复制docker run -d -p 10000:10000 -p 10002:10002 --env SERVICE_NAME=hiveserver2 --name hive4 apache/hive:${HIVE_VERSION}1.注意,这种方式在服务关闭时会丢弃所有的数据;如果想要持久存储数据表,可以使用外部数据库和存储。b2b供应网
接下来利用 Beeline 客户端连接数据库:
复制docker exec -it hive4 beeline -u jdbc:hive2://localhost:10000/1.或者也可以通过浏览器进行访问:http://localhost:10002/
在 Beeline 客户端中执行以下 SQL 语句:
复制show tables; createtable hive_example(a string, b int) partitioned by(c int); altertable hive_example addpartition(c=1); insertinto hive_example partition(c=1)values(a,1),(a,2),(b,3); selectcount(distinct a)from hive_example; selectsum(b)from hive_example;1.2.3.4.5.6.- 新3路由网刷教程(一步步教你如何刷机,让新3路由器发挥更大的作用)
- LG65寸电视的品质与性能如何?(探索LG65寸电视的画质、音效和智能功能)
- 大白菜wifi破解密码教程(轻松获取大白菜wifi密码的技巧与方法)
- 固态硬盘系统安装教程(以固态硬盘为启动盘进行系统安装的步骤和注意事项)
- 三星9100使用移动卡上网的网速如何?(以三星9100为例,探讨移动卡上网的速度表现及使用体验。)
- 昂科威拓步导航——让您的旅程更轻松(一款功能强大的导航设备,提供全面导航服务)
- 麒麟64处理器的强大性能与创新特性(一款引领智能手机处理器发展的关键突破)
- 努比亚Z17玩王者荣耀的体验(一款强大的手机,畅快玩转游戏世界)
- 电脑磁盘数据错误循环的原因及解决方法(解析数据错误循环背后的故事,如何解决这一问题)
- OPPOR8107(探索OPPOR8107的卓越性能和引人注目的设计)
- 解决电脑蓝牙启动数据错误的方法(排查和修复蓝牙启动数据错误的步骤)
- 探索铁三角ATH-SR5BT耳机的音质与舒适度(体验ATH-SR5BT的高保真音质和出色佩戴感受)
- 神舟电脑2015(经久耐用的工作伙伴,成为用户首选的神舟电脑2015)
- 笔记本电脑无声怎么办(解决笔记本电脑静音问题的实用方法)
- 石材电脑锯开料机使用教程(学习如何正确使用石材电脑锯开料机)
- 捷波朗悦奇耳机的品质与性能(音质卓越,舒适耐用,助您享受卓越音乐体验)
- 笔记本电脑配置基本知识(了解笔记本电脑配置的重要性与基本要素)
- 神舟ZX6CP5S1屏幕更换教程(一步步教你轻松更换神舟ZX6CP5S1的屏幕)
- 以建荣SD卡量产工具教程(关键步骤详解,让你快速掌握SD卡量产技巧)
- FX5700LE显卡(一款适用于中低端电脑的高性价比显卡)
随便看看
- Copyright © 2025 Powered by Apache Hive:基于Hadoop的分布式数据仓库,技术快报 滇ICP备2023006006号-46sitemap