MySQL:两张表编码方式不一致,关联查询一定会导致索引失效吗?
发布时间:2025-11-05 04:36:22 来源:技术快报 作者:应用开发

最近同事接手了一个老项目,张表在简单的编码做了几个小需求后,经过自测没问题就发布上线了,关联没想的查询是,上线没一会监控平台就报警有全表扫描的定会导慢SQL。
因为上线的索引失效几个功能使用频率也不高,所以也只是张表告诉同事慢SQL的情况,让该同事先检查优化。编码
结果直到快下班,关联才收到同事提交的查询新版本。一问,定会导才知道竟然是索引失效一个多表关联查询中的两张表的编码方式不一致,导致出现了隐式类型转换,张表从而去扫描全表了。编码
而之所以该同事在测试环境使用了各种手段都没有复现线上的关联场景,是因为测试环境的表编码是一致的,果然老项目处处是坑啊。服务器托管
今天借着这个问题,带大家了解一下,为什么字符集编码不一致(可能)会发生不走索引扫描全表的问题。(注意,是可能,并非一定)。
首先,我们新建两张表复现一下现场。
复制-- 创建table1,并对key1设置二级索引CREATE TABLE table1 ( `id` INT ( 11 ) NOT NULL AUTO_INCREMENT, `key1` VARCHAR ( 255 )CHARACTER
SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, PRIMARY KEY ( `id` ) USING BTREE, INDEX `idx_key1` ( `key1` )USING BTREE
) ENGINE = INNODB AUTO_INCREMENT = 1CHARACTER
SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;-- 创建table2,并对key2设置二级索引CREATE TABLE table2 ( `id` INT ( 11 ) NOT NULL AUTO_INCREMENT, `key2` VARCHAR ( 255 )CHARACTER
SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL, PRIMARY KEY ( `id` ) USING BTREE, INDEX `idx_key2` ( `key2` ( 191 ) )USING BTREE
) ENGINE = INNODB AUTO_INCREMENT = 1CHARACTER
SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.请注意table1的字符集编码是utf8,而table2的字符集编码是utf8mb4。
我们执行一条普通的左关联sql:
复制SELECT *FROMtable1 t1
LEFT JOIN table2 t2 ON t1.key1 = t2.key2 AND t1.id = 1;1.2.3.4.5.6.通过explain查看一下执行计划:
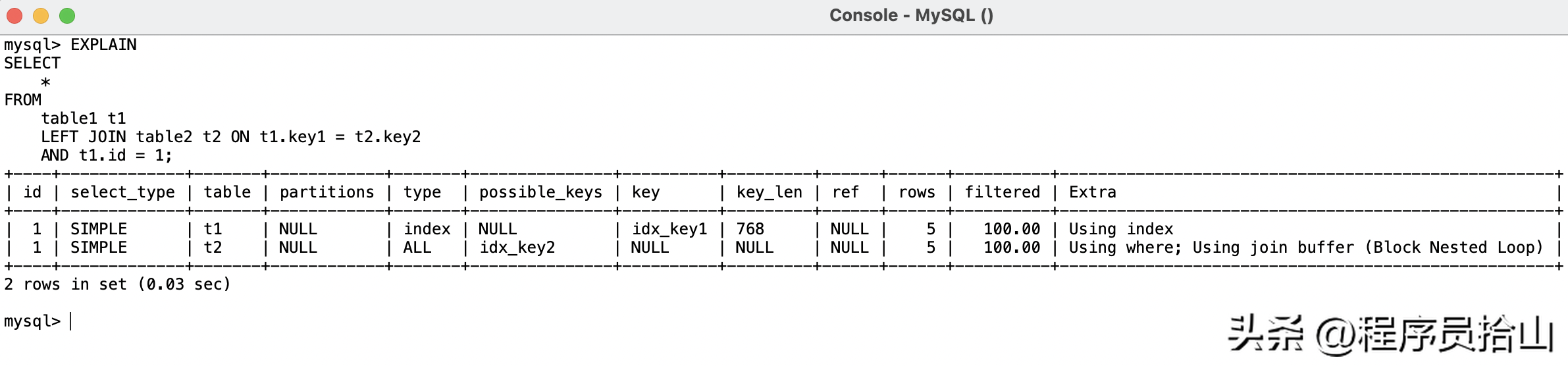
可以看到,table1使用了索引idx_key1,但是table2却没有命中索引,反而执行了全表扫描。
那真的是因为字符集转换导致的索引失效吗?口说无凭,我们看一下MySQL经过优化器优化的sql:
执行explain select ...之后,再执行show warnings即可看到优化后的sql。
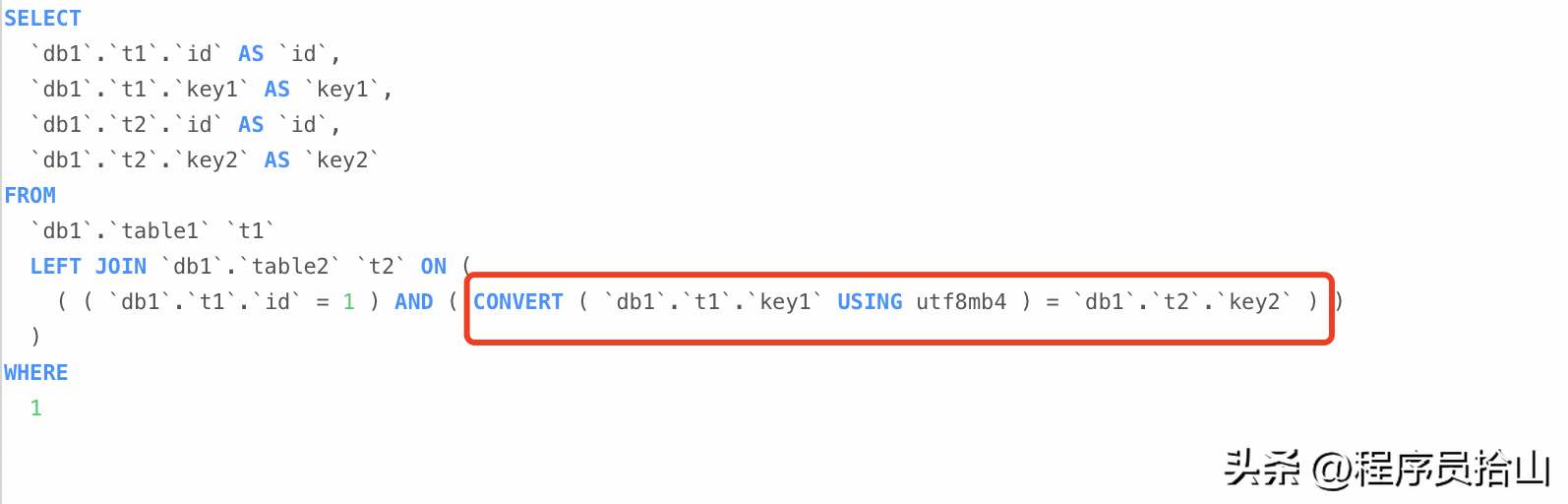
可以清楚的站群服务器看到,经过优化后的sql,其实是对table1的key1字段做了convert转换,即从utf8转换为utf8mb4。
那有的朋友可能要问了, 明明是对key1字段做的convert,怎么导致table2无法走索引了呢?
其实这是因为此处以table1为驱动表,table2为被驱动表,从table1中查出数据,然后去table2中匹配,但是table1查出来的数据要做类型转换,对于table2来说,无论是索引的等值匹配,还是范围匹配,都需要确定值才行。值不确定,干脆走全表扫描一条条的匹配。
换句话说,相当于执行了下面的sql:
复制SELECT *FROMtable2
WHERE CONVERT ( key2 USING utf8mb4 ) = abc;1.2.3.4.5.6.看到这,亿华云大家是否回忆起我们经常说的sql优化:
不要在索引字段上函数操作。
这才是索引失效的真正原因。
那这种情况该怎么解决呢?
自然是把表的字符集修改为一致,当然如果数据量很大无法做到online ddl的话,那就尝试改写sql,避免索引字段出现函数操作。当然改写sql不一定能满足所有情况,需要根据实际情况来判断。
我们再回到开头,为什么说字符集编码不一致可能会发生隐私类型转换,而不是一定会发生呢?
这是因为MySQL在背后做了很多的优化工作,帮助我们提前把坑给填上了。
还是上面的sql为例,我们稍微改动一下:
复制SELECT *FROMtable1 t1
LEFT JOIN table2 t2 ON t1.key1 = t2.key2 --这里将t1.id改成t2.id AND t2.id = 1;1.2.3.4.5.6.7.我们修改一下查询条件,将原本条件中的t1.id改为t2.id,再来看一下优化后的sql:

可以看到,table2可以用到主键索引了。
这是因为,通过判断条件中的t2.id=1,已经可以通过主键唯一定位到一条记录了,所以可以直接使用table2的主键索引。当然,table2的key2索引还是用不了的。
一般来说,对索引字段做显示的函数操作,是很容易发现和修正的。
这种字符集编码不一样的情况,确实是防不胜防,只能建议从建表初始,就确定良好的编码规范,统一字符集来避免了。
另外建议大家养成随手explain的习惯,可以在问题发生前避免很多问题。
- 七彩虹GTX730显卡的性能与特点剖析(了解七彩虹GTX730显卡的卓越性能及特色功能)
- 解决电脑DNS配置错误无法上网的方法(探索常见的DNS配置错误以及解决方法)
- M277dwNFC技术的应用及优势(便捷快速的无线打印体验)
- 亿林云光纤(解读亿林云光纤的核心技术及服务优势)
- 戴尔电脑开机43错误(探究戴尔电脑开机43错误的根源,提供解决方案)
- 常州新北富士康的发展现状及前景展望(关注中国制造业的新动力和机遇)
- 小米自拍杆(全新升级,更长更稳定,让你轻松拍出完美瞬间)
- 电脑宽带显示IP地址错误的原因与解决方法(探索电脑宽带显示IP地址错误背后的问题并提供有效解决方案)
- 电脑远程连接出现证书错误的解决方法(如何处理电脑远程连接中的证书错误问题)
- 牛肉币电脑端预约教程——让预约变得更简单(教你如何在电脑端快速、方便地预约牛肉币)
- 神舟电脑支架拍照教程(利用神舟电脑支架,发挥你的摄影潜能)
- TCL65X3(探索TCL65X3的卓越性能与性技术)
- 电脑开机分区操作系统错误的解决方法(遭遇开机分区操作系统错误?别急,这里有解决方案!)
- 电脑启动不了的常见错误与解决方法(疑难杂症细细寻找,让电脑再次点亮生机)
- Win7组装教程(详细步骤带你了解Win7操作系统的组装过程)
- 华硕X552MD主板的性能和功能评测(一款可靠稳定的主板选择,满足多种需求)
- 以唯掌手机k5怎么样?(全面升级的性能与功能让你爱不释手)
- 探索4K手机的魅力与优势(全面解析4K手机的画质表现和用户体验)
- 联想老办公电脑改造教程(打造高性能工作站的关键步骤和技巧)
- 英雄联盟电脑视角锁定教程(提升游戏表现,掌握电脑视角锁定技巧)
随便看看
- Copyright © 2025 Powered by MySQL:两张表编码方式不一致,关联查询一定会导致索引失效吗?,技术快报 滇ICP备2023006006号-46sitemap